Lab 5: File system, Spawn and Shell

系统中的spawn功能(fork+exec,主要是exec需要加载硬盘中的二进制文件)和console功能(调用相关的功能时要么是遍历文件系统,要么也是加载相应的二进制文件。重定向、管道等特性也是文件系统的特性)都需要文件系统的支持。
File system preliminaries
JOS的文件系统基本特征有文件的增删读写,支持文件的结构化。
JOS文件系统仅有单用户,因此不支持多用户的权限管理。同时不支持硬链接,symbolic links, 时间戳和特殊设备的读取。
On-Disk File System Structure
大多数UNIX文件系统将硬盘划分成两种区域:
- inode region
- data regions
每一个文件都会分配一个inode。inode会保存一个文件的重要的元数据,并且指向自己的数据块。
目录含有文件夹的名字和指向inode的指针。
如果一个文件的inode被多个文件目录包含,那么可以说这是文件硬链接。
JOS系统不会支持硬链接,并且JOS不支持inode的管理。JOS仅仅通过简单的保存一个文件或者目录的元数据,从而达到索引的目的(后面有图进行详细的说明)
JOS允许用户态的程序读取目录的元数据,因此实现ls功能将是轻而易举的事情。这样做的缺点是应用程序文件格式需要依赖JOS目录元数据的格式,使得兼容性变得特别的差。(相当于是固定的简陋格式很难允许其他格式的程序进行运行,而inode有更好调节的灵活性)
Sectors and Blocks
硬盘的基本单位是sector = 512Bytes, JOS读取的基本单位是block = 4096Bytes。
Superblocks
superblock保存了文件系统总共有多少的block和根目录位置,索引其他文件夹或者文件的指针。
一般保存在block 1。之所以没保存在block 0是预留位置给boot loader和partition table。
许多系统中保存着多个superblock,因此当其中的一个块损坏后,其他的仍然能够保持整个文件系统正常的运转。
File Meta-data
JOS将文件的元数据通过mmap进行分配:
if ((diskmap = mmap(NULL, nblocks * BLKSIZE, PROT_READ|PROT_WRITE,
MAP_SHARED, diskfd, 0)) == MAP_FAILED)
panic("mmap %s: %s", name, strerror(errno));
只用记住分配了一块内存给了File 结构体元数据,使得之后能够进行指针的操作。
JOS有10个直接访问块和1个间接访问块,总共能够管理的数据大小为(10+1024)*4KB 约等于4MB。
如果想要支持更大文件的管理,则需要2个间接或者3次间接寻址的方式(xv6中就支持这种操作)。

其中管理文件数据的元数据File是通过mmap进行分配的。
Directories versus Regular Files
文件夹和普通的文件通过元数据type进行区分,JOS都是通过File指针保存到元数据中,从而进行结构的索引的。

若想找到某个文件或者文件夹,那么就去遍历10个direct block和1024个indirect block。通过比对路径的类型和文件名,从而确定是否找到并返回。其中每一个block中保存的都是struct File,如下图所示:
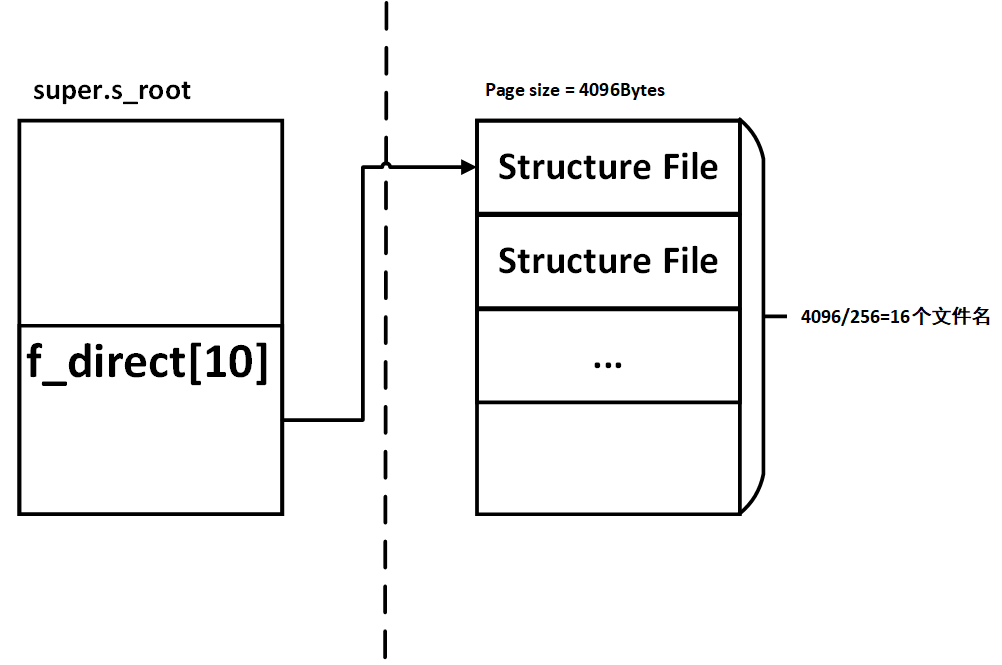
若文件的类型是文件,而不是文件夹,那么每一个索引的数据项10+1024=1034项中保存的都是硬盘的块号。(可以在file_block_walk和file_get_block中的函数逻辑知道)
The File System
这一部分的实验并不需要我们去实现一个文件系统,但是我们需要对实现提供的一些文件的操作函数比较的熟悉。本实验新增代码约有5k行。
Disk Access
JOS使用 IDE disk driver去访问硬盘数据。我们需要修改相应的文件服务进程的权限,从而使得只有该进程能够获取硬盘的数据。
通过polling和programmed I/O,我们就可以在用户态实现磁盘数据的读取。当然我们可以基于中断来实现该功能,但是这相对而言比较的难。
x86通过%eflags中的IOPL位来判断保护模式下的代码能否使用特殊的设备I/O指令如IN和out。
在JOS中,我们希望仅有file system environment(文件服务系统)有上面设备I/O的权限,其他的进程统统都没有该权限。
exercise 1
i386_init中,通过
ENV_TYPE_FS判断是否是文件服务系统进程,之后给操作文件的特权。
首先我们在创建进程的时候,带有进程的种类:
ENV_CREATE(fs_fs, ENV_TYPE_FS);
由于文件服务系统的特殊性,要在初始化eflags寄存器的时候进行判断,代码如下:
if (type == ENV_TYPE_FS) {
newenv->env_tf.tf_eflags |= FL_IOPL_MASK;
}
question 1
怎么保证进程切换,这样的 device I/O priviledge能够保持?
因为该权限保存在进程的帧中,当陷入其他进程时,都会弹出相应进程当时寄存器的值,而不会错误的使用文件服务系统特有的寄存器值。如何保存栈帧和弹出栈帧,我们在之前的实验中就已经详细的阐述了。
注意本实验fs.img我们设置的是disk 1, boot loader设置的disk 0。
The Block Cache
通过系统的虚拟内存管理,我们实现一个简单的文件的buffer cache。
我们的文件系统会映射到[DISKMAP, DIAKMAP+DISKMAX] = [0X10000000, 0xD0000000] = 3G大小。
并且这一部分会映射到文件服务系统的页目录和页表中。但是这样的作法在目前的操作系统中并不正确,因为磁盘的大小动辄上T。
如果将磁盘的整个内容移动到内存中,那么代价将是非常大的。因此,我们借鉴lab4中的思想,先做映射,当发生缺页中断了,那么再进行相应的映射。
exercise 2
实现
fs/bc.c中的bc_pgfault和flush_block函数。实现
bc_pgfault时注意下面的事项:
- addr可能不是和一个block对齐的
- ide_read操作的单位是sectors(512Bytes),而不是block(4096Bytes)。
如果某页没有被映射或者不为脏,那么flush_block不干任何事情。
其中脏位(PTE_D)是由硬件进行设置的,并且保存在uvpt中。
flush_block使用sys_page_map来清除PTE_D位。
fs_init中有着如何使用block cache的例子。
当block cache初始化完后(实际上仅仅是设置了一个bc_pgfault的处理函数),当我们访问相关的内容时,如果内容不在内存中,那么就会触发缺页中断。但是整个过程就像是内容就在内存中一样。
static void
bc_pgfault(struct UTrapframe *utf)
{
void *addr = (void *) utf->utf_fault_va;
uint32_t blockno = ((uint32_t)addr - DISKMAP) / BLKSIZE;
int r;
// Check that the fault was within the block cache region
if (addr < (void*)DISKMAP || addr >= (void*)(DISKMAP + DISKSIZE))
panic("page fault in FS: eip %08x, va %08x, err %04x",
utf->utf_eip, addr, utf->utf_err);
// Sanity check the block number.
if (super && blockno >= super->s_nblocks)
panic("reading non-existent block %08x\n", blockno);
// Allocate a page in the disk map region, read the contents
// of the block from the disk into that page.
// Hint: first round addr to page boundary. fs/ide.c has code to read
// the disk.
//
// LAB 5: you code here:
// envid 传入 0表示当前进程。
addr =(void *) ROUNDDOWN(addr, PGSIZE);
if ( (r = sys_page_alloc(0, addr, PTE_P|PTE_W|PTE_U)) < 0) {
panic("in bc_pgfault, sys_page_alloc: %e", r);
}
// size_t secno = (addr - DISKMAP) / BLKSIZE;
if ( (r = ide_read(blockno*BLKSECTS, addr, BLKSECTS)) < 0) {
panic("in bc_pgfault, ide_read: %e",r);
}
// Clear the dirty bit for the disk block page since we just read the
// block from disk
// 清除脏位
if ((r = sys_page_map(0, addr, 0, addr, uvpt[PGNUM(addr)] & PTE_SYSCALL)) < 0)
panic("in bc_pgfault, sys_page_map: %e", r);
// Check that the block we read was allocated. (exercise for
// the reader: why do we do this *after* reading the block
// in?)
if (bitmap && block_is_free(blockno))
panic("reading free block %08x\n", blockno);
}
// Flush the contents of the block containing VA out to disk if
// necessary, then clear the PTE_D bit using sys_page_map.
// If the block is not in the block cache or is not dirty, does
// nothing.
// Hint: Use va_is_mapped, va_is_dirty, and ide_write.
// Hint: Use the PTE_SYSCALL constant when calling sys_page_map.
// Hint: Don't forget to round addr down.
void
flush_block(void *addr)
{
uint32_t blockno = ((uint32_t)addr - DISKMAP) / BLKSIZE;
if (addr < (void*)DISKMAP || addr >= (void*)(DISKMAP + DISKSIZE))
panic("flush_block of bad va %08x", addr);
// LAB 5: Your code here.
addr = (void *)ROUNDDOWN(addr, PGSIZE);
if (va_is_mapped(addr) && va_is_dirty(addr)) {
ide_write(blockno*BLKSECTS, addr , BLKSECTS);
int r;
// Clear the dirty bit for the disk block page since we just read the
// block from disk
//下面的语句就是为了清空脏位
if ((r = sys_page_map(0, addr, 0, addr, uvpt[PGNUM(addr)] & PTE_SYSCALL)) < 0)
panic("in flush_block, sys_page_map: %e", r);
}
//panic("flush_block not implemented");
}
The Block Bitmap
我们可以使用bitmap来记录硬盘块的使用情况。每一位都能记录一个块是否被使用。bitmap大小为4096Bytes=40968bits,那么一共管理$4096 8 * 4KB = 128MB$反正目前是够用的。
exercise 3
使用free_block为模板,来实现
fs/fs.c中的alloc_block函数。我们需要找到第一个没有使用的硬盘块,将其标记被使用,并且返回序号
注意当我们改变了bitmap时,应该将其立刻写回硬盘中,以此来保证文件系统的一致性。
// Search the bitmap for a free block and allocate it. When you
// allocate a block, immediately flush the changed bitmap block
// to disk.
//
// Return block number allocated on success,
// -E_NO_DISK if we are out of blocks.
//
// Hint: use free_block as an example for manipulating the bitmap.
uint32_t *bitmap; // bitmap blocks mapped in memory
int
alloc_block(void)
{
// The bitmap consists of one or more blocks. A single bitmap block
// contains the in-use bits for BLKBITSIZE blocks. There are
// super->s_nblocks blocks in the disk altogether.
// LAB 5: Your code here.
size_t i;
//bitmap 1表示是空闲的,0表示的是占用的
for(i=1; i < super->s_nblocks; i++) {
if (block_is_free(i)) {
bitmap[i/32] &= ~(1<<(i%32));
flush_block(&bitmap[i/32]);//将bitmap在硬盘中刷新
return i;
}
}
//panic("alloc_block not implemented");
return -E_NO_DISK;
}
File Operations
熟读fs/fs.c中的代码,有较为熟悉的了解。
exercise 4
实现
file_block_walk和file_get_block。
file_block_walk就是不断递归,寻找绝对路径中的文件夹和文件,而file_get_block就是获得文件块中具体的块号。
下面是寻找某个文件过程的示意图:
// Find the disk block number slot for the 'filebno'th block in file 'f'.
// Set '*ppdiskbno' to point to that slot.
// The slot will be one of the f->f_direct[] entries,
// or an entry in the indirect block.
// When 'alloc' is set, this function will allocate an indirect block
// if necessary.
//
// Returns:
// 0 on success (but note that *ppdiskbno might equal 0).
// -E_NOT_FOUND if the function needed to allocate an indirect block, but
// alloc was 0.
// -E_NO_DISK if there's no space on the disk for an indirect block.
// -E_INVAL if filebno is out of range (it's >= NDIRECT + NINDIRECT).
//
// Analogy: This is like pgdir_walk for files.
// Hint: Don't forget to clear any block you allocate.
static int
file_block_walk(struct File *f, uint32_t filebno, uint32_t **ppdiskbno, bool alloc)
{
int r;
if (filebno >= NDIRECT + NINDIRECT)
return -E_INVAL;
if (filebno < NDIRECT) {
if (ppdiskbno)
*ppdiskbno = f->f_direct + filebno;
return 0;
}
if (!alloc && !f->f_indirect)
return -E_NOT_FOUND;
//间接寻找
if (!f->f_indirect) {
if ((r = alloc_block()) < 0)
return -E_NO_DISK;
f->f_indirect = r;
memset(diskaddr(r), 0, BLKSIZE);
flush_block(diskaddr(r));
}
//这里保存的是硬盘块号,有点不理解
if (ppdiskbno)
*ppdiskbno = (uint32_t*)(diskaddr(f->f_indirect)) + filebno - NDIRECT;
return 0;
}
// Set *blk to the address in memory where the filebno'th
// block of file 'f' would be mapped.
//
// Returns 0 on success, < 0 on error. Errors are:
// -E_NO_DISK if a block needed to be allocated but the disk is full.
// -E_INVAL if filebno is out of range.
//
// Hint: Use file_block_walk and alloc_block.
int
file_get_block(struct File *f, uint32_t filebno, char **blk)
{
// LAB 5: Your code here.
int r;
uint32_t *ppdiskbno;
if ((r = file_block_walk(f, filebno, &ppdiskbno, 1)) < 0)
return r;
if (*ppdiskbno == 0) {
if ((r = alloc_block()) < 0)
return -E_NO_DISK;
*ppdiskbno = r;
memset(diskaddr(r), 0, BLKSIZE);
flush_block(diskaddr(r));
}
*blk = diskaddr(*ppdiskbno);
return 0;
}
file_block_walk and file_get_block是file system的马力。file_read和file_write正是基于上面的两个函数实现调用的。
The file system interface
JOS将文件功能单独的独立出来一个文件服务进程,并且其他的进程没有权限调用相关的文件操作函数(由于eflags寄存器的限制)。因此,如果其他进程想要对文件进行操作,那么必须和文件系统进程进行通信,通信的结构如下:
Regular env FS env
+---------------+ +---------------+
| read | | file_read |
| (lib/fd.c) | | (fs/fs.c) |
...|.......|.......|...|.......^.......|...............
| v | | | | RPC mechanism
| devfile_read | | serve_read |
| (lib/file.c) | | (fs/serv.c) |
| | | | ^ |
| v | | | |
| fsipc | | serve |
| (lib/file.c) | | (fs/serv.c) |
| | | | ^ |
| v | | | |
| ipc_send | | ipc_recv |
| | | | ^ |
+-------|-------+ +-------|-------+
| |
+-------------------+
exercise 5
实现/fs/serv.c中的serve_read函数
// Read at most ipc->read.req_n bytes from the current seek position
// in ipc->read.req_fileid. Return the bytes read from the file to
// the caller in ipc->readRet, then update the seek position. Returns
// the number of bytes successfully read, or < 0 on error.
int
serve_read(envid_t envid, union Fsipc *ipc)
{
struct Fsreq_read *req = &ipc->read;
struct Fsret_read *ret = &ipc->readRet;
if (debug)
cprintf("serve_read %08x %08x %08x\n", envid, req->req_fileid, req->req_n);
// Lab 5: Your code here:
int r;
struct OpenFile *of;
if ( (r = openfile_lookup(envid, req->req_fileid, &of) )< 0)
return r;
if ( (r = file_read(of->o_file, ret->ret_buf, req->req_n, of->o_fd->fd_offset))< 0)
return r;
// then update the seek position.
of->o_fd->fd_offset += r;
return r;
}
exercise 6
实现
fs/serv.c中的serve_write函数,实现lib/file.c中的devfile_write函数。
// Write req->req_n bytes from req->req_buf to req_fileid, starting at
// the current seek position, and update the seek position
// accordingly. Extend the file if necessary. Returns the number of
// bytes written, or < 0 on error.
int
serve_write(envid_t envid, struct Fsreq_write *req)
{
if (debug)
cprintf("serve_write %08x %08x %08x\n", envid, req->req_fileid, req->req_n);
// LAB 5: Your code here.
int r;
struct OpenFile *of;
int reqn;
if ( (r = openfile_lookup(envid, req->req_fileid, &of)) < 0)
return r;
reqn = req->req_n > PGSIZE? PGSIZE:req->req_n;
if ( (r = file_write(of->o_file, req->req_buf, reqn, of->o_fd->fd_offset)) < 0)
return r;
of->o_fd->fd_offset += r;
return r;
//panic("serve_write not implemented");
}
devfile_write函数:
static ssize_t
devfile_write(struct Fd *fd, const void *buf, size_t n)
{
// Make an FSREQ_WRITE request to the file system server. Be
// careful: fsipcbuf.write.req_buf is only so large, but
// remember that write is always allowed to write *fewer*
// bytes than requested.
// LAB 5: Your code here
int r;
if (n > sizeof(fsipcbuf.write.req_buf))
n = sizeof(fsipcbuf.write.req_buf);
fsipcbuf.write.req_fileid = fd->fd_file.id;
fsipcbuf.write.req_n = n;
memmove(fsipcbuf.write.req_buf, buf, n);
if ((r = fsipc(FSREQ_WRITE, NULL)) < 0)
return r;
return r;
//panic("devfile_write not implemented");
}
Spawning Processes
spawn = fork + exec
exercise 7
实现kern/syscall.c中的
sys_env_set_trapframe。
// Set envid's trap frame to 'tf'.
// tf is modified to make sure that user environments always run at code
// protection level 3 (CPL 3), interrupts enabled, and IOPL of 0.
//
// Returns 0 on success, < 0 on error. Errors are:
// -E_BAD_ENV if environment envid doesn't currently exist,
// or the caller doesn't have permission to change envid.
static int
sys_env_set_trapframe(envid_t envid, struct Trapframe *tf)
{
// LAB 5: Your code here.
// Remember to check whether the user has supplied us with a good
// address!
struct Env *env;
int r;
if ( (r = envid2env(envid, &env, 1)) < 0)
return r;
// 什么时候会出现没有权限访问的问题?
user_mem_assert(env, tf, sizeof(struct Trapframe), PTE_U);
// 直接整个结构体也是可以赋值的
env->env_tf = *tf;
env->env_tf.tf_cs |= 0x3;
env->env_tf.tf_eflags &= (~FL_IOPL_MASK);
env->env_tf.tf_eflags |= FL_IF;
return 0;
//panic("sys_env_set_trapframe not implemented");
}
Sharing library state across fork and spawn
分享的部分其实就是为了能够进行内存的共享,从而能够进行内容的互换与通信。
之前所有做的父进程与子进程之间内存都是共享读的,一旦某一个进程改变了其中的内容,那么父进程和子进程分享读的内容就分道扬镳了。
为了能够实现页的共享,JOS做了下面的设计与规定:
新增符号位PTE_SHARE,使得有该标记的页能够被共享。
exercise 8
更改
lib/fork.c中duppage函数的实现,如果页有PTE_SHARE标记位,那么直接进行copy。同理,实现
lib/spawn.c中的copy_shared_pages函数,它会将目前进程中所有的页表遍历一遍,然后copy那么标有PTE_SHARE的页。
static int
duppage(envid_t envid, unsigned pn)
{
int r;
// LAB 4: Your code here.
int ret;
void *addr = (void *)(pn * PGSIZE);
// 新增的分支判断
if (uvpt[pn] & PTE_SHARE) {
if((ret = sys_page_map(0, addr, envid, addr, uvpt[pn] & PTE_SYSCALL)) <0 )
return ret;
}
else if((uvpt[pn] & PTE_W) || (uvpt[pn] & PTE_COW)){
if(sys_page_map(0, addr, envid, addr, PTE_U | PTE_COW | PTE_P) < 0)
panic("duppage: parent->child sys_page_map failed.");
if(sys_page_map(0, addr, 0, addr, PTE_U | PTE_COW | PTE_P) < 0)
panic("duppage: self sys_page_map failed.");
} else {
if(sys_page_map(0, addr, envid, addr, PTE_P | PTE_U) < 0)
panic("duppage: single sys_page_map failed.");
}
return 0;
}
// Copy the mappings for shared pages into the child address space.
static int
copy_shared_pages(envid_t child)
{
// LAB 5: Your code here.
size_t pn;
int r;
struct Env *e;
for (pn = PGNUM(UTEXT); pn < PGNUM(USTACKTOP); ++pn) {
if ( (uvpd[pn >> 10] & PTE_P) && (uvpt[pn] & PTE_P) ) {
if (uvpt[pn] & PTE_SHARE) {
if ( (r = sys_page_map(thisenv->env_id, (void *)(pn*PGSIZE), child, (void *)(pn*PGSIZE), uvpt[pn] & PTE_SYSCALL )) < 0)
return r;
}
}
}
return 0;
}
pipe的本质
在JOS中,pipe本质上就是一段父进程和子进程共享的一段内存。很多的示意图会将管道画成一个队列的形式,其实并不正确,下面通过pipe的初始化和使用,对pipe的原理进行说明。
一般父进程和子进程进行通信,假设子进程读,父进程写,那么一般的套路为:
char *msg = "Now is the time for all good men to come to the aid of their party.";
char buf[100];
int p[2];
pipe(p);
int pid = fork();
if(pid == 0){
//子进程程序
close(p[1]);
i = readn(p[0], buf, sizeof buf-1);
exit();
}
else{
//父进程程序
close(p[0]);
i = write(p[1], msg, strlen(msg));
close(p[1]);
}
wait(pid);
pipe读写的过程:写和读操作都是在同一个内存块的。
if ((r = sys_page_map(0, va, 0, fd2data(fd1), PTE_P|PTE_W|PTE_U|PTE_SHARE)) < 0)
该语句表示的就是两个fd指向的是同一个虚拟的页面。
close(p[i])实际上是减少该内存页的引用次数。
读是在一个轮询的状态,因此当一个进程完成了写操作,那么就应该立刻close(p[1]),从而能够减少该共享页的引用次数。而读进程一旦知道了所有的写操作都完成后,那么就会结束这个读的操作。如果不及时的关闭写,那么读进程就会进入死循环(写进程是正常结束的)。
同样的,如果写进程写满了pipe buffer,并且检测到没有读管道,那么会立刻停止写的操作。

上图是整个文件系统大概的工作流程,fd实际上是dev(即硬盘)、管道和console的抽象。在lab6中也是socket的抽象。
我们特意简化其中的一些要素。
下面是整个pipe工作的原理图:

fd0(读操作),fd1(写操作)都指向了同样的一块虚拟地址空间,这个空间就是pipe。其中p_rpos是读指针,p_wpos是写指针,它们共同的数据区域为p_buf。
当某个进程写完了,应该及时的关闭管道,这样才能够及时的通知读进程,告诉它读完就可以结束了。
ret = pageref(fd) == pageref(p);
这个语句中,当写进程在写的时候,pageref(fd) < pageref(p),一旦close(fd[i]),相关的pageref(p)就会减少。注意p只有一个,而fd有两个fd0和fd1。
知道了上面的原理,我们修改上面的代码:
if(pid == 0){
//子进程程序
close(p[1]);
i = readn(p[0], buf, sizeof buf-1);
exit();
}
else{
//父进程程序
//close(p[0]); //仅仅把这个注释了
i = write(p[1], msg, strlen(msg));
close(p[1]);
}
wait(pid);
这样也是对的。
一开始pipe()+fork(),使得pageref(p)=4, pageref(fd0)=2, pageref(fd1)=2。
我们只要保证写进程写完后pageref(fd1) = 0就能保证程序的正确的运行,而不会使得读进程陷入死循环。
The keyboard interface
这一部分的实现和在monitor中的输入不太一样,这一部分是在用户态的程序进行输入的接受。
exercise 9
In your
kern/trap.c, callkbd_intrto handle trapIRQ_OFFSET+IRQ_KBDandserial_intrto handle trapIRQ_OFFSET+IRQ_SERIAL.
// Handle keyboard and serial interrupts.
// LAB 5: Your code here.
if (tf->tf_trapno == IRQ_OFFSET + IRQ_KBD) {
kbd_intr();
return;
}
if (tf->tf_trapno == IRQ_OFFSET + IRQ_SERIAL) {
serial_intr();
return;
}
The Shell
运行make run-icode或者运行make run-icode-nox,使得能够通过键盘输入运行简单的应用程序。
exercise 10
进行相关的实现,使得该程序支持输入的重定向,支持
sh <script操作。
解析读入<后面的文件,然后将该文件作为运行程序的输入即可。
case '<': // Input redirection
// Grab the filename from the argument list
if (gettoken(0, &t) != 'w') {
cprintf("syntax error: < not followed by word\n");
exit();
}
// Open 't' for reading as file descriptor 0
// (which environments use as standard input).
// We can't open a file onto a particular descriptor,
// so open the file as 'fd',
// then check whether 'fd' is 0.
// If not, dup 'fd' onto file descriptor 0,
// then close the original 'fd'.
// LAB 5: Your code here.
if ( (fd = open(t, O_RDONLY) )< 0 ) {
fprintf(2,"file %s is no exist\n", t);
exit();
}
if (fd != 0) {
dup(fd, 0);
close(fd);
}
break;
//panic("< redirection not implemented");
最后的结果:
