Lab 1: Booting a PC
本科的时候老师拉跨的讲课水平,使得我对操作系统的理解依旧只会开关机。并且,我对操作系统的知识非常的感兴趣,因此想要深入的进行学习。网上搜索,发现非常多的该课程的攻略。如何使得自己的攻略与众不同呢?同时如何让自己更好的掌握某项知识,最好的方法就是讲给别人听。于是,在一个月之前,我在一个夜黑风高的晚上,录制了讲解的视频,链接如下。
由于录制的屏幕适配性,所以缺少了右边和下边的部分屏幕内容,但是并不影响观看。
录完该视频后,我反复看了这个视频,发现有很大的问题——虽然自己能够理解,但是讲的不清楚。讲的不成体系,所有的知识点非常的零散,并且是参考官方的tutorial讲解的,其中遗漏了很多的细节。我个人觉得我需要一个同好与我battle,这样可能能够更好的让我知道怎么讲更合适。
于是,我暂缓了录视频,开始做其他的lab。
最近,我开始重拾了该教程,目的就是做到与众不同。但是,我发现真的很难。与此同时,我尽可能多的去收集了一些操作系统的一些更深层次的设计原理,使我对其有更深的理解。如BIOS为什么从0x7c00进行启动,其背后居然有一段历史原因【4】。加入了更多的基础的讲解,如汇编语言、内联汇编、图解ELF,stack等等。lab1讲解攻略配有18张图,总字数约为一万字。
写这个攻略前我已经充分熟悉lab1了,但是依旧花了我四天内所有的空闲时间。
课程代码GitHub链接:
该文档的集合链接:
如果你觉得这个攻略对你有帮助,欢迎在githhub上star设置follow。
当然,如果你发现本文本有逻辑上的错误,欢迎提issue or pull request。
思维导图

Part 1: PC Bootstrap
exercise 1 熟悉汇编语言
熟悉汇编语言,其中可以特别需要阅读材料Brennan's Guide to Inline Assembly。这个链接中很好的说明了本实验使用的汇编语言版本AT&T与Intel版本的区别,并且有有关内联汇编比较简洁够用的语法介绍。
Simulating the x86
操作系统是真实的运行在硬件之上的。本课程为了调试的简便性,使用了QEMU,该工具能够虚拟各种硬件设备,供本实验操作系统JOS进行调用,并且JOS是运行在QEMU之上。
cd lab
make qemu # 编译运行JOS
make qemu-nox # 不使用虚拟化的VGA窗口
make qemu-gdb # 开启gdb调试,这个时候需要在另外一个命令行使用make gdb
make qemu-nox-gdb #
如果想要推出qemu,使用Ctrl+a -> x。
另外,如果想要将该系统运行到真是的硬件设备上,那么需要将obj/kern/kernel.img烧录到硬盘扇区最开始的地方。
The PC's Physical Address Space
+------------------+ <- 0xFFFFFFFF (4GB)
| 32-bit |
| memory mapped |
| devices |
| |
/\/\/\/\/\/\/\/\/\/\
/\/\/\/\/\/\/\/\/\/\
| |
| Unused |
| |
+------------------+ <- depends on amount of RAM
| |
| |
| Extended Memory |
| |
| |
+------------------+ <- 0x00100000 (1MB)
| BIOS ROM |
+------------------+ <- 0x000F0000 (960KB)
| 16-bit devices, |
| expansion ROMs |
+------------------+ <- 0x000C0000 (768KB)
| VGA Display |
+------------------+ <- 0x000A0000 (640KB)
| |
| Low Memory |
| |
+------------------+ <- 0x00000000
这是一个主机的物理内存的分布情况。
一开始的8088处理器只能寻16位地址,能够管理1MB的物理内存。之所以16位地址能够管理1MB的物理内存地址是因为采用(CS:IP)的寻址方式,physical address = 16*segment + offset。
你问为什么不采用physical address = (segment<<16) + offset,这样有4GB的内存可以寻址啊,并且是可以实现的,个人猜想可能和当时的硬件发展有关。
BIOS(basic input output system)的初始化程序一开始在不可擦除的flash中保存,随着内存的发展目前存放在非易失可擦写的内存中。
一般超过32位地址都是用于PCI设备寻址使用。
又由于现在有些设备支持超过4GB的内存,因此,BIOS需要为哪些PCI设备预留一些空间,提供访问,即哪怕你的物理内存超过了4GB,有些部分依旧是不能访问的,需要预留给物理设备。
The ROM BIOS
Type "apropos word" to search for commands related to "word".
+ target remote localhost:26000
warning: A handler for the OS ABI "GNU/Linux" is not built into this configurati
on
of GDB. Attempting to continue with the default i8086 settings.
The target architecture is assumed to be i8086
[f000:fff0] 0xffff0: ljmp $0xf000,$0xe05b
0x0000fff0 in ?? ()
+ symbol-file obj/kern/kernel
IBM PC BIOS第一条指令执行地址在0xffff0。可以看到在BIOS分配的区域非常上面,因此后面第一条指令就是跳到相对低的地址进行指令的执行。
exercise 2 查看BIOS执行的指令
看看BIOS开始的阶段都干啥了?
具体指令的汇总:
1 0xffff0: ljmp $0xf000, $0xe05b #跳转到0xfe05b
2 0xfe05b: cmpl $0x0, $cs:0x6ac8 #根据cs:0x6ac8是否为0,进行跳转
3 0xfe062: jne 0xfd2e1 #无跳转
4 0xfe066: xor %dx, %dx #%dx清零
5 0xfe068: mov %dx, %ss #%ss置零
6 0xfe06a: mov $0x7000, %esp
7 0xfe070: mov $0xf34d2,%edx
8 0xfe076: jmp 0xfd15c
9 0xfd15c: mov %eax, %ecx
10 0xfd15f: cli #BIOS的启动不允许中断,关闭中断
11 0xfd160: cld #设置指令增长的方向
12 0xfd161: mov $0x8f, %eax
13 0xfd167: out %al, $0x70 #0x70和0x71是用于操作CMOS 的端口
14 0xfd169: in $0x71, %al #12-14三条指令是用于关闭不可屏蔽中断
15 0xfd16b: in $0x92, %al
16 0xfd16d: or $0x2, %al
17 0xfd16f: out %al, $0x92
18 0xfd171: lidtw %cs:0x6ab8 #将0xf6ab8处的数据读入到中断向量表寄存(IDTR)
19 0xfd177: lgdtw %cs:0x6a74 #并将0xf6a74的数据读入到全局描述符表格寄存器(GDTR)中
20 0xfd17d: mov %cr0, %eax
21 0xfd180: or $0x1, %eax
22 0xfd184: mov %eax, %cr0 #CR0末位置1,进入保护模式
23 0xfd187: ljmpl $0x8, $0xfd18f
24 0xfd18f: mov $0x10, %eax
25 0xfd194: mov %eax, %ds
26 0xfd196: mov %eax, %es
27 0xfd198: mov %eax, %ss
28 0xfd19a: mov %eax, %fs
29 0xfd19c: mov %eax, %gs
30 0xfd19e: mov %ecx, %eax #第23~29 步用于重新加载段寄存器,在加载完GDTR 寄存器后需要 #刷新所有的段寄存器的值
其中有一段需要特殊解释,就是加载GDT(Global Descriptor Table )的一个操作,具体的解释可以参考【1】:
23 0xfd187: ljmpl $0x8, $0xfd18f
24 0xfd18f: mov $0x10, %eax
25 0xfd194: mov %eax, %ds
26 0xfd196: mov %eax, %es
27 0xfd198: mov %eax, %ss
28 0xfd19a: mov %eax, %fs
29 0xfd19c: mov %eax, %gs
30 0xfd19e: mov %ecx, %eax
GDT长度为48B,结构如下:
|LIMIT|----BASE----|
低 高
高32位表示这个表所在的位置,低16位表示表的大小。
ljmp能够跳转的范围是(1<<16),占用的字节数为3B,jmp能够跳转的范围为-127+128,占用指令大小为1B。
并且上面的ljmp跳转用法为:
Long jump, use 0xfebc for the CS register and 0x12345678 for the EIP register:
# 并且CS寄存器的值不能使用mov进行修改,但是下面的指令可以修改CS寄存器的值为0xfebc
ljmp $0xfebc, $0x12345678
为什么要将所有与段寄存有关的寄存器都置为0x10。
这是段寄存器结构:

0x10 = 00010000 = 000010 0 00
也就是说优先级是最高的,选择的表是GDT,segment index = 2。
Q:为什么加载GDT需要刷新段寄存器呢?
因为GDT初始化了表的位置,剩下的索引需要依靠段寄存器,进行偏移索引。
最后总结BIOS做的事情:
- 初始化IDT和GDT
- 初始化VGA设备,PCI bus挂载的各类设备
- 找到物理存储设备,并且找到一个bootable disk,将运行的权利转移到disk。
Part 2: The Boot Loader
磁盘被分割为sector的最小基本单位,1 sector=512B。
后来随着硬件的发展,PC主要也需要能够从CD中启动,而CD中分割的基本单位为1 sector = 2048B。方式略有不同,具体不同需要参考其他的资料。
boot loader主要做的两件事情:
- 从16-bit的实模式转化到32-bit的保护模式。转换到32位的保护模式有诸多的好处,我们在之后转换额过程中进行具体的讨论。
- 第二点是将kernel代码从硬盘中读取出来。这个过程涉及到特殊的I/O指令。对理解操作系统整体的框架来说,这并不是一个重要的点。
exercise 3
熟悉GDB的调试指令。
使用GDB单步进行调试,调试的时候可以参考
obj/boot/boot.asm这个反汇编中的指令,因为CPU就是按照这个文件里面的指令进行的。readsect()里面调用的指令和读取完了执行了什么指令。
这一部分主要是熟悉使用GDB结合.asm文件进行调试。实际上我们使用的调试环境是cgdb,因此能够实时的看到反汇编的代码。当然调试的过程中需要对整体有一个理解的过程,因此这个时候需要借鉴.asm。
Q1: 什么时候处理器开始执行32位的代码?什么引起了从16-转换到了32-bit?
ljmp $PROT_MODE_CSEG, $protcseg
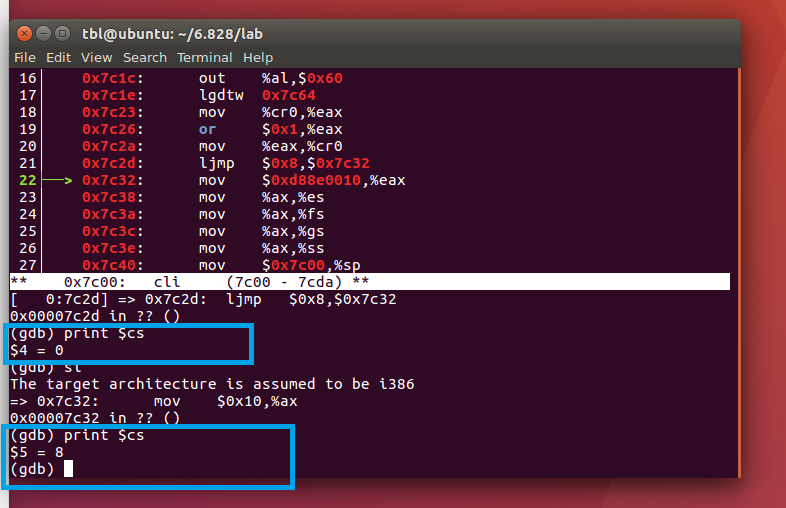
可以看到,在执行这个指令之前,地址的寻址方式为[0:7c2d],一旦执行完这条语句,寻址方式变为0x7c32。
Q2: bootloader执行的最后一个语句?kernel执行的第一条语句为?
movw $0x1234,0x472 # warm boot
Q3: kernel执行的第一条指令?
同Q2的第二个答案。
movw $0x1234,0x472 # warm boot
Q4: boot loader是怎么知道读取多少个sectors到内存的?
这些信息保存到ELF header中,在编译的时候就已经决定了。
关于程序是怎么加载到内存中并且进行运行的,主要看两张图进行理解:
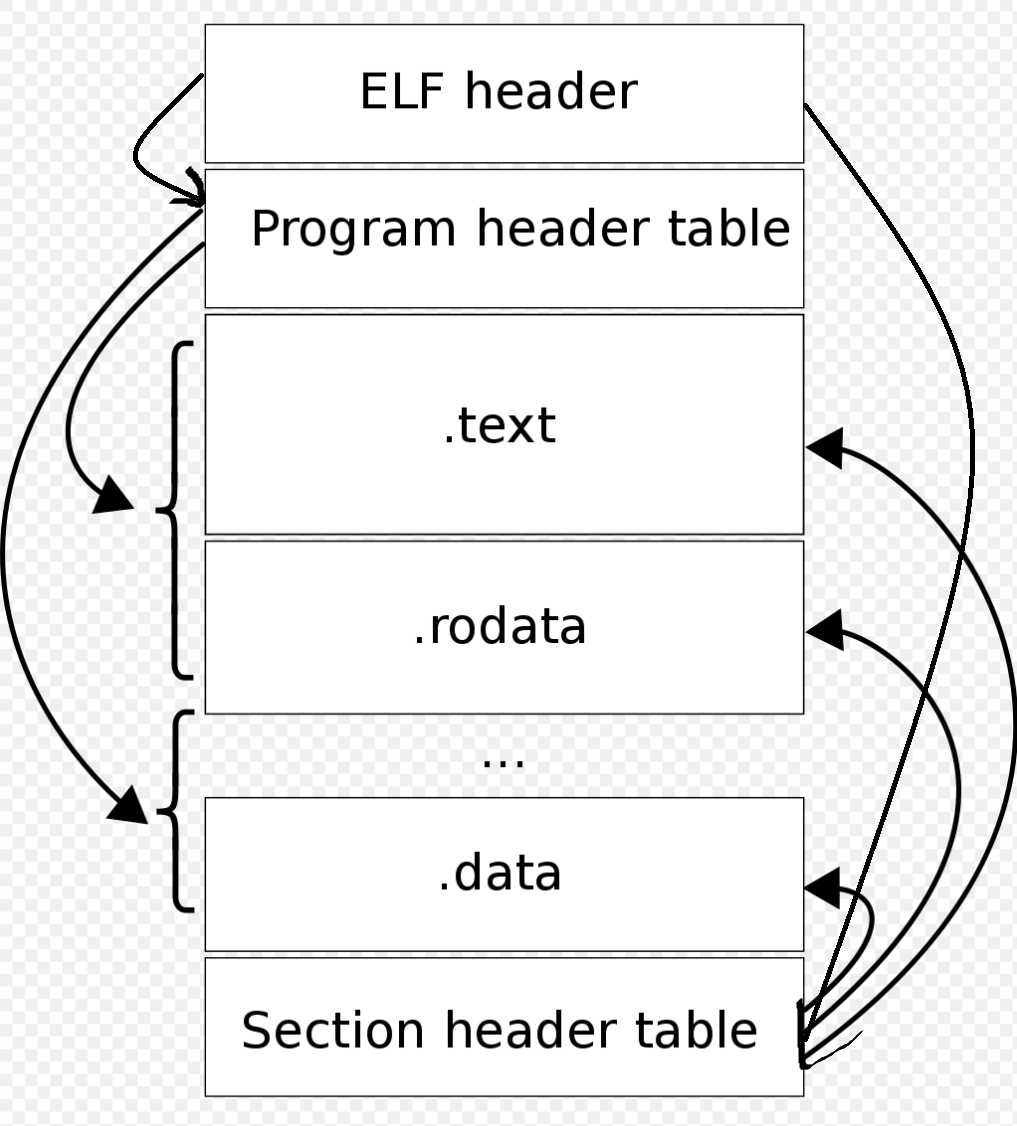
可以看到可以从ELF header读取到Program header table和Section header table的信息,之后能够从这两个表中读取更详细的信息。
通过下面的图,我们可以知道ELF运作更多的细节:
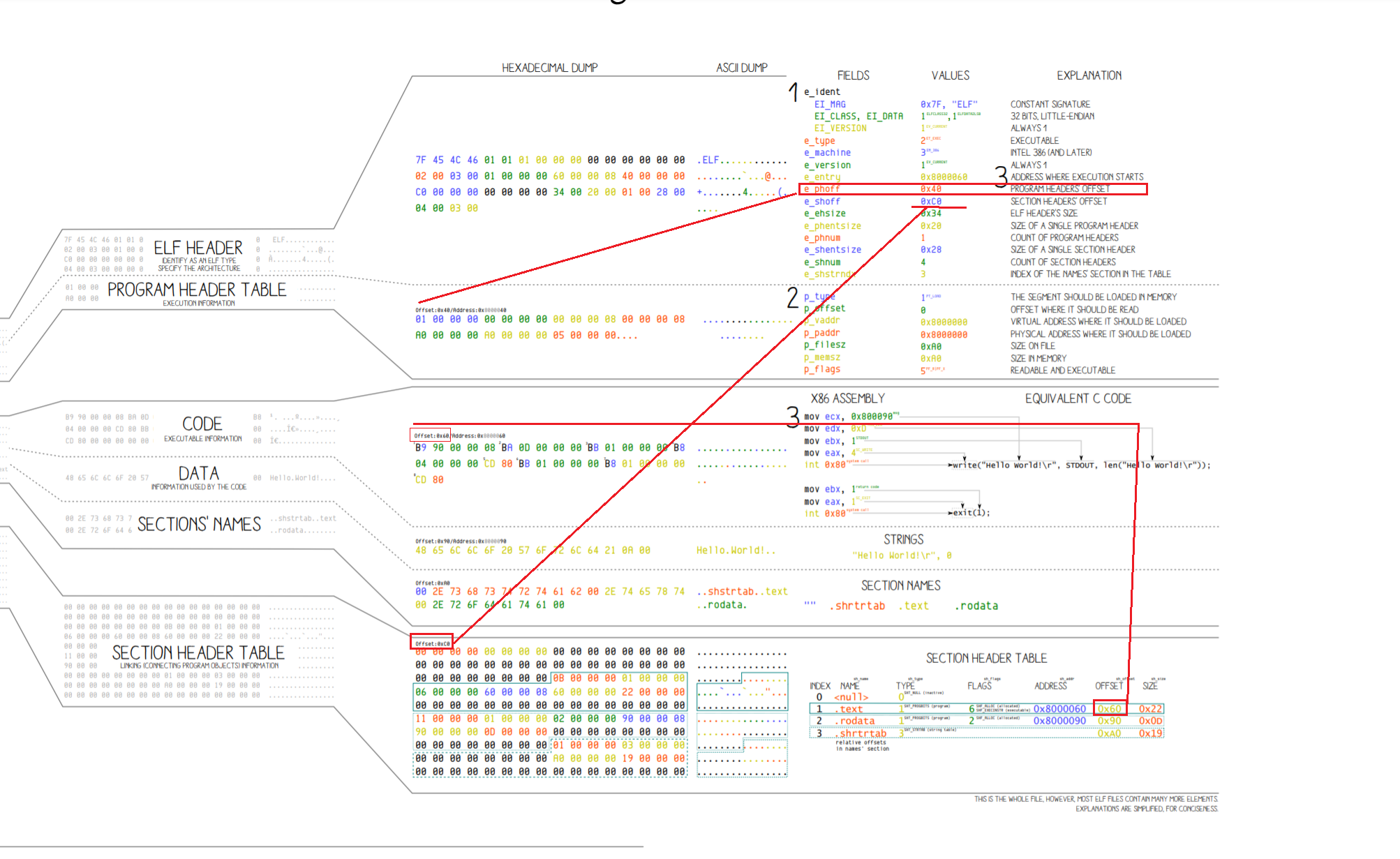
这张图上传后压缩肯定看不清了,建议直接下载看原图:原图链接
在ELF header中记录着program header table的个数,每个entry的大小,偏移量。而program header table中每一个具体的信息都能够帮助我们将具体的指令,数据读入到内存中。
section header table在读取数据进内存没有什么用。
真正起到将数据读到内存的流程就是ELF header -> 查找 program header table -> 具体的数据。
Loading the Kernel
exercise 4
首先熟悉C语言的指针。一个比较简短的教材。
解释下面的程序输出内容。
#include <stdio.h>
#include <stdlib.h>
void
f(void)
{
int a[4];
int *b = malloc(16);
int *c;
int i;
printf("1: a = %p, b = %p, c = %p\n", a, b, c);
c = a;
for (i = 0; i < 4; i++)
a[i] = 100 + i;
c[0] = 200;
printf("2: a[0] = %d, a[1] = %d, a[2] = %d, a[3] = %d\n",
a[0], a[1], a[2], a[3]);
c[1] = 300;
*(c + 2) = 301;
3[c] = 302;
printf("3: a[0] = %d, a[1] = %d, a[2] = %d, a[3] = %d\n",
a[0], a[1], a[2], a[3]);
c = c + 1;//实际上偏移了4B
*c = 400;
printf("4: a[0] = %d, a[1] = %d, a[2] = %d, a[3] = %d\n",
a[0], a[1], a[2], a[3]);
c = (int *) ((char *) c + 1);
*c = 500;
printf("5: a[0] = %d, a[1] = %d, a[2] = %d, a[3] = %d\n",
a[0], a[1], a[2], a[3]);
b = (int *) a + 1;
c = (int *) ((char *) a + 1);
printf("6: a = %p, b = %p, c = %p\n", a, b, c);
}
int
main(int ac, char **av)
{
f();
return 0;
}
pinter.c的输出内容为:
1: a = 0x7ffec83ade20, b = 0x13e3010, c = 0xf0b6ff
2: a[0] = 200, a[1] = 101, a[2] = 102, a[3] = 103
3: a[0] = 200, a[1] = 300, a[2] = 301, a[3] = 302
4: a[0] = 200, a[1] = 400, a[2] = 301, a[3] = 302
5: a[0] = 200, a[1] = 128144, a[2] = 256, a[3] = 302
6: a = 0x7ffec83ade20, b = 0x7ffec83ade24, c = 0x7ffec83ade21
其他的输出原因比较的简单,我们仅仅分析第5条的输出结果:
修改前a内存的分布
0000 0000 高地址
0000 0000
0000 0001
0010 1101
0000 0000
0000 0000
0000 0001
1001 0000 低地址 a+1
修改后a内存的分布
0000 0000 高地址
0000 0000
0000 0001
---------
0000 0000
0000 0000
0000 0001
1111 0100
---------
1001 0000 低地址 a+1
这个例子也证明该PC的内存使用的是小端法,即数字的低位保存在低地址。
该实验主要想要证明的是,不同类型的偏移量是不同的,和变量的类型有关。
下面一部分是熟悉ELF(Executable and Linkable Format)。
二进制文件有一个固定长度的ELF header,紧随其后的是可变长的program header,其中包含着需要被读取到内存中的program section。
其中需要特别留意几个常用的section:
- .text: 这个程序中可执行的指令。
- .rodata: 只读的数据,一般是C语言的常量,比如printf中保存的值。
.data: 程序中初始化了的全局变量。
.bss: 程序中未初始化的全局变量,紧跟在.data后面。由于这些值在程序运行的时候都是0,因此在ELF记录的时候,仅需要记录这一段的起始地址和大小。等加载(program loader)时,再将对应的空间进行初始化。
输入:
tbl@ubuntu:~/6.828/lab$ objdump -h obj/kern/kernel
输出
tbl@ubuntu:~/6.828/lab$ objdump -h obj/kern/kernel
obj/kern/kernel: file format elf32-i386
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00001941 f0100000 00100000 00001000 2**4
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .rodata 0000079c f0101960 00101960 00002960 2**5
CONTENTS, ALLOC, LOAD, READONLY, DATA
2 .stab 00003b89 f01020fc 001020fc 000030fc 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
3 .stabstr 0000197f f0105c85 00105c85 00006c85 2**0
CONTENTS, ALLOC, LOAD, READONLY, DATA
4 .data 0000a300 f0108000 00108000 00009000 2**12
CONTENTS, ALLOC, LOAD, DATA
5 .bss 00000648 f0112300 00112300 00013300 2**5
CONTENTS, ALLOC, LOAD, DATA
6 .comment 00000035 00000000 00000000 00013948 2**0
CONTENTS, READONLY
需要特别注意VMA=link address=vaddr(虚拟地址), LMA=load address=paddr(物理地址)。
The load address of a section is the memory address at which that section should be loaded into memory.
The link address of a section is the memory address from which the section expects to execute.
一般link和load地址都是相同的,如下例:
tbl@ubuntu:~/6.828/lab$ objdump -h obj/boot/boot.out
obj/boot/boot.out: file format elf32-i386
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000186 00007c00 00007c00 00000074 2**2
CONTENTS, ALLOC, LOAD, CODE
1 .eh_frame 000000a8 00007d88 00007d88 000001fc 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
2 .stab 00000720 00000000 00000000 000002a4 2**2
CONTENTS, READONLY, DEBUGGING
3 .stabstr 0000088f 00000000 00000000 000009c4 2**0
CONTENTS, READONLY, DEBUGGING
4 .comment 00000035 00000000 00000000 00001253 2**0
CONTENTS, READONLY
我们对下面的
tbl@ubuntu:~/6.828/lab$ objdump -x obj/kern/kernel
obj/kern/kernel: file format elf32-i386
obj/kern/kernel
architecture: i386, flags 0x00000112:
EXEC_P, HAS_SYMS, D_PAGED
start address 0x0010000c
Program Header:
LOAD off 0x00001000 vaddr 0xf0100000 paddr 0x00100000 align 2**12
filesz 0x00007604 memsz 0x00007604 flags r-x
LOAD off 0x00009000 vaddr 0xf0108000 paddr 0x00108000 align 2**12
filesz 0x0000a948 memsz 0x0000a948 flags rw-
STACK off 0x00000000 vaddr 0x00000000 paddr 0x00000000 align 2**4
filesz 0x00000000 memsz 0x00000000 flags rwx
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00001941 f0100000 00100000 00001000 2**4
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .rodata 0000079c f0101960 00101960 00002960 2**5
CONTENTS, ALLOC, LOAD, READONLY, DATA
2 .stab 00003b89 f01020fc 001020fc 000030fc 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
3 .stabstr 0000197f f0105c85 00105c85 00006c85 2**0
CONTENTS, ALLOC, LOAD, READONLY, DATA
4 .data 0000a300 f0108000 00108000 00009000 2**12
CONTENTS, ALLOC, LOAD, DATA
5 .bss 00000648 f0112300 00112300 00013300 2**5
CONTENTS, ALLOC, LOAD, DATA
6 .comment 00000035 00000000 00000000 00013948 2**0
CONTENTS, READONLY
SYMBOL TABLE:
f0100000 l d .text 00000000 .text
f0101960 l d .rodata 00000000 .rodata
Program Header中LOAD表示会加载到内存中,可以从filesz和vaddr推断:.text,.rodata...stabstr这些部分在第一个LOAD部分,后面的所有sections都在第二个LOAD中。
exercise 5
修改boot loader的地址,然后看看会发生什么错误。
BIOS从0x7c00这个地址开始执行boot loader中的程序,因此这个地址是这个sector的load address。并且这个地址可以在boot/Makefrag进行修改。
将原来的值修改为0x8c00,我们重新在0x7c00这个地址打上断点,发现还是在能够进入boot loader的,并且似乎没有什么变化。我们si单步执行下去,发现在这样的语句出现了错误:
ljmp $0x8, $0x8c32
第二个值原来是0x7c32可以看到是这里产生了改变。

并且为什么我们修改了这个加载的地址,BIOS启动执行的第一条指令的地址依旧是0x7c00呢?这个其实有一个典故,和早期的计算机的设计是有关系的【3】。历史上有一种机器的内存为32KB,0x7C00-0x7DFF中前512B存放硬盘的引导程序,后512B存放其中产生的数据。
我们可以看到boot loader的load address和link address是一致的,但是在kernel部分并不是一致的。也就是说,kernel希望boot loader能够在低地址加载自己,在高地址(0xf0000...)执行自己。这个怎么实现的,后面会详细的讨论。
查看程序执行的开始地址:
tbl@ubuntu:~/6.828/lab$ objdump -f obj/kern/kernel
obj/kern/kernel: file format elf32-i386
architecture: i386, flags 0x00000112:
EXEC_P, HAS_SYMS, D_PAGED
start address 0x0010000c
exercise 6
使用x/Nx address查看内存中的内容
当从BIOS进入到boot loader时在地址0x00100000的内存存储的内容。
进入到kernel 0x00100000存的值。
一般情况下1 word = 2 Bytes
两处内存的值分别为:

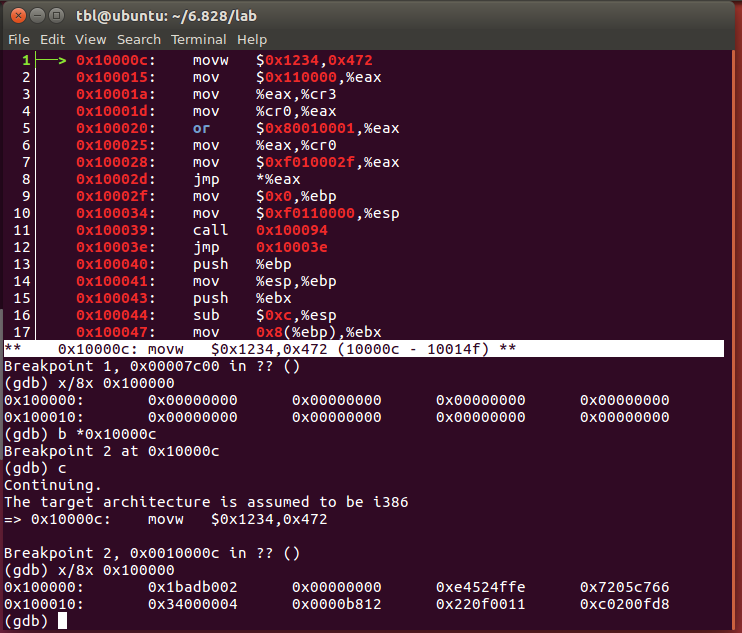
我们再查看obj/kern/kernel.asm中指令:
entry:
movw $0x1234,0x472 # warm boot
f0100000: 02 b0 ad 1b 00 00 add 0x1bad(%eax),%dh
f0100006: 00 00 add %al,(%eax)
f0100008: fe 4f 52 decb 0x52(%edi)
f010000b: e4 .byte 0xe4
f010000c <entry>:
f010000c: 66 c7 05 72 04 00 00 movw $0x1234,0x472
f0100013: 34 12
从下面这个片段,我们知道0x34存在地址0xf0100013, 0x12存到了0xf0100014,但是在GDB展示的时候是逆过来的,说明内部是倒序的。
f010000c: 66 c7 05 72 04 00 00 movw $0x1234,0x472
f0100013: 34 12
我们发现,GDB一个32位的值的展示,地址是从高->低的。
可以发现和上面图片所展示的内容一致。
Part 3: The Kernel
从这一部分开始,我们就要开始写一些代码了!
Using virtual memory to work around position dependence
我们在做之前的练习5的时候发现,kernel的link address和load address是不相同的,这一部分我们就详细的进行探索。
设置kernel的link address在/kern/kernle.ld中进行设置,可以明显的看到这样的一个语句:
/* Link the kernel at this address: "." means the current address */
. = 0xF0100000;
系统的内核一般是将内核程序放到非常高的虚拟空间进行执行,低一些的空间留给用户执行程序。尽管内核运行在较高的虚拟地址中,但是实际保存的物理地址依旧是1MB之上,也就是在BIOS之上。
在本实验中,我们仅仅会使用到0xf0000000-0xf0400000这一段的虚拟地址,我们将其映射到0x00000000-0x00400000 。并且我们也将0x00000000-0x00400000映射到同样一块物理地址。目前仅使用了4MB大小的内存。
关于目前的这个系统是怎么进行内存的映射的,主要使用了cr3和cr0。
并且寻址方式如下:

不同的是,目前lab1仅仅初始化了page directory中的两条数据,和page table中所有的数据,如下面的红框标注所示:

cr3寄存器确定了这张表的基地址
# Load the physical address of entry_pgdir into cr3. entry_pgdir
# is defined in entrypgdir.c.
movl $(RELOC(entry_pgdir)), %eax
movl %eax, %cr3
exercise 7
在
movl %eax, %cr0语句停止执行,观察前后地址0x00100000和0xf0100000内容的变化。将上面这句注释了,查看会发生什么?第一条崩溃的指令
我们在0x10000c打上断点,并且在该语句前后查看此时两个地址中的内容:
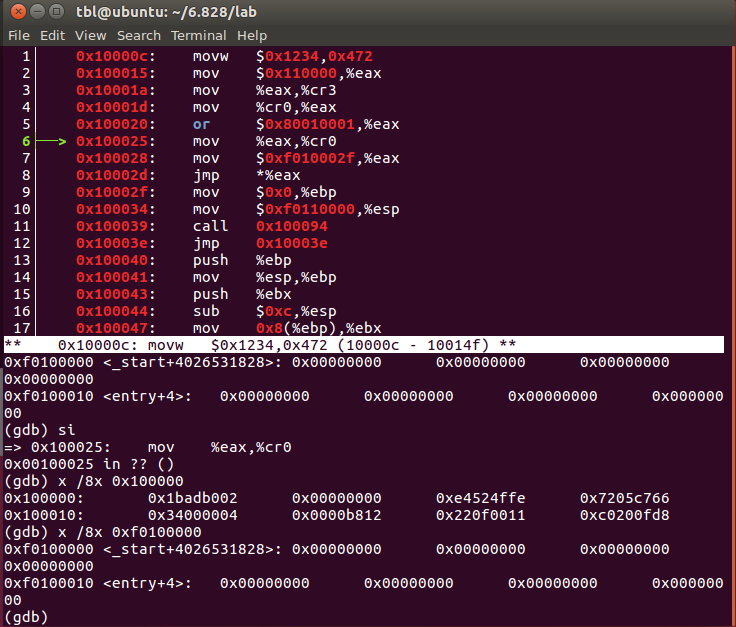
此时两个地址内容是不同的。
一旦执行了该语句:

两个地址指向了同样的内容。
后来我们将这个语句进行注释,重新执行,发现在这个语句发生崩溃:
mov $relocated, %eax
f0100028: b8 2f 00 10 f0 mov $0xf010002f,%eax
jmp *%eax
f010002d: ff e0 jmp *%eax
原因也很简单,0xf010002f这个地址并没有被映射,因此无法访问,产生错误。
Formatted Printing to the Console
这一部分就是教我们printf的底层原理是什么,相当于手写printf。
exercise 8
找到cprintf("6828 decimal is %o octal!\n", 6828);使之能够输出进制为8。
找到相应的需要实现的部分在printfmt.c,代码如下:
// (unsigned) octal
case 'o':
// Replace this with your code.
num = getuint(&ap, lflag);
base = 8;
goto number;
break;
首先我们了解一下c语言中的变长参数机制。
首先验证函数调用的压栈机制,运行如下的程序:
// gcc -m32 -o test ./test.c
// 注意是32位的编译器进行编译
#include<stdio.h>
void test(int a,int b,int c,int d,int e,int f,int g,int h)
{
printf("%p\n%p\n%p\n%p\n%p\n%p\n%p\n%p\n",&a,&b,&c,&d,&e,&f,&g,&h);
}
int main(int argc,char *argv[])
{
int a = 1;
int b = 2;
int c = 3;
int d = 4;
int e = 5;
int f = 6;
int g = 7;
int h = 8;
test(a,b,c,d,e,f,g,h);
return 0;
}
输出结果为:
0xff842030
0xff842034
0xff842038
0xff84203c
0xff842040
0xff842044
0xff842048
0xff84204c
我们知道栈空间应该是从高地址向低地址的,因此压栈的顺序是从右往左。
编译器有三个宏定义:
va_list :存储参数的类型信息,32位和64位实现不一样。 void va_start ( va_list ap, paramN ); 参数: ap: 可变参数列表地址 paramN: 确定的参数 功能:初始化可变参数列表,会把paraN之后的参数放入ap中
type va_arg ( va_list ap, type ); 功能:返回下一个参数的值。
void va_end ( va_list ap ); 功能:完成清理工作。
可变参数函数实现的步骤如下:
- 1.在函数中创建一个va_list类型变量
- 2.使用va_start对其进行初始化
- 3.使用va_arg访问参数值
- 4.使用va_end完成清理工作
结合具体的例子来看:
//来源:公众号【编程珠玑】
#include <stdio.h>
/*要使用变长参数的宏,需要包含下面的头文件*/
#include <stdarg.h>
/*
* getSum:用于计算一组整数的和
* num:整数的数量
*
* */
int getSum(int num,...)
{
va_list ap;//定义参数列表变量
int sum = 0;
int loop = 0;
va_start(ap,num);
/*遍历参数值*/
for(;loop < num ; loop++)
{
/*取出并加上下一个参数值*/
sum += va_arg(ap,int);
}
va_end(ap);
return sum;
}
int main(int argc,char *argv[])
{
int sum = 0;
sum = getSum(5,1,2,3,4,5);
printf("%d\n",sum);
return 0;
}
可以看到,当调用变长函数的时候,左边的参数必须是固定的,并且变长参数列表应该和固定参数中一一对应。
这下其实我们就能够理解其中的原理了。
接下来进行下面的实验,查看各类打印函数的调用关系。
kern/printf.c, lib/printfmt.c, and kern/console.c
从左往右,越来越底层。其中printf.c定义了一个比较简单的供用户使用的抽象函数,我们知道变长参数函数调用的原理后,就能够明白printfmt.c是在解析固定的那个字符串,按照规定的格式读出变长参数。最后通过最为底层的console.c与底层的硬件进行交互。
Q1:printf.c是怎么去调用console.c中的函数的?
printf.c 调用console.c中的cputchar 函数进行显示输出。
Q2:解释下面的代码是干什么的?
1 if (crt_pos >= CRT_SIZE) {
2 int i;
3 memmove(crt_buf, crt_buf + CRT_COLS, (CRT_SIZE - CRT_COLS) * sizeof(uint16_t)); //memmove(void *dst, const void *src, size_t len)
4 for (i = CRT_SIZE - CRT_COLS; i < CRT_SIZE; i++)
5 crt_buf[i] = 0x0700 | ' ';
6 crt_pos -= CRT_COLS;
7 }
当显示器显示的字符数量超过限制的时候,首先是将crt_buf + CRT_COLS开始到结束的字符移到最开始的地方,这个时候末尾的 CRT_COLS个显示位置空出来了,并且这个时候将其置为空格。
Q3: 单步执行下面的语句
int x = 1, y = 3, z = 4;
cprintf("x %d, y %x, z %d\n", x, y, z);
我们将其插入到init.c中。
使用下面的常用的几条命令:
n: 执行单条c语言语句,不进入到具体的函数中。
s(tep): 进入到具体的函数中。
bt(backtrace): 打印出函数调用栈。
得到如下的结果:

使用x/s fmt打印出了常量字符串
x/3wx打印出来了可变参数内容
课程教程中让我们在cons_putc, va_arg和vcprintf每次调用的参数变化。
其中va_arg由于是一个宏定义,我们换成其他的函数getuint打断点,并且能够观察ap(可变参数)的变化。
cons_putc函数是每次输出一个字符。
我们分别在三个函数上打上断点,观察它们的变化:
| 函数 | 值 | 说明 | |
|---|---|---|---|
| 1 | vcprintf | fmt=“x %d, y %x, z %d \n”, ap=1,3,4 | |
| 2 | cons_putc | c=120 | 'x' |
| 3 | cons_putc | c=32 | ' ' |
| 4 | va_arg | 调用前ap=1,3,4 调用后ap=3,4 | |
| 5 | cons_putc | 49 | '1' |
| 6 | cons_putc | 44 | ',' |
| 7 | cons_putc | 32 | ' ' |
| 8 | cons_putc | 121 | 'y' |
| 9 | cons_putc | 32 | ' ' |
| 10 | va_arg | 调用前ap=3,4 调用后ap=4 | |
| 11 | cons_putc | 51 | '3' |
| 12 | cons_putc | 44 | ',' |
| 13 | cons_putc | 32 | ' ' |
| 14 | cons_putc | 122 | 'z' |
| 15 | cons_putc | 32 | ' ' |
| 16 | va_arg | 调用前ap=4 调用后ap 为空 | |
| 17 | cons_putc | 52 | '4' |
| 18 | cons_putc | 10 | '\n' |
Q4: 运行下面的代码,并且解释为什么是这样的输出结果。
unsigned int i = 0x00646c72;
cprintf("H%x Wo%s", 57616, &i);
输出He110 World
$(57616){10} = (e110){16}$
由于是小端存储,在一个字节内,最开始的地方是地位,并且我们找到反汇编语言的地方:
//cprintf("x %d, y %x, z %d\n", x, y, z);
unsigned int i = 0x00646c72;
//地址 c8 c9 ca cb cc cd ce
f01000c8: c7 45 f4 72 6c 64 00 movl $0x646c72,-0xc(%ebp)
cprintf("H%x Wo%s", 57616, &i);
f01000cf: 83 c4 0c add $0xc,%esp

我们按照地址增的顺序打印了内容,进一步验证了小端法的保存方式。
并且ASCII码0x72='r', 0x6c='l',0x64='d',0x00='\0'(null)
Q5: 运行cprintf("x=%d y=%d", 3);并且解释输出的结果。
我们首先查看这个部分的反汇编部分
cprintf("x=%d y=%d", 3);
f01000c8: 83 c4 08 add $0x8,%esp
f01000cb: 6a 03 push $0x3
f01000cd: 68 b2 19 10 f0 push $0xf01019b2
f01000d2: e8 d5 08 00 00 call f01009ac <cprintf>
然后观察栈空间的变化:
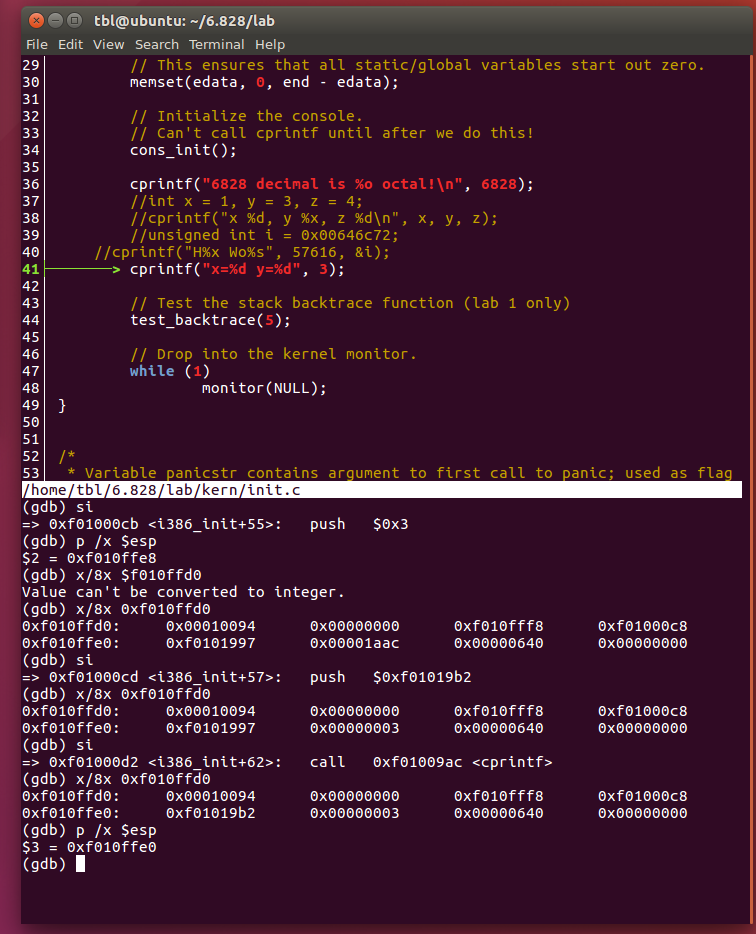
发现栈中依次压入了0x3, 0xf01019b2确实在内存中显示了。
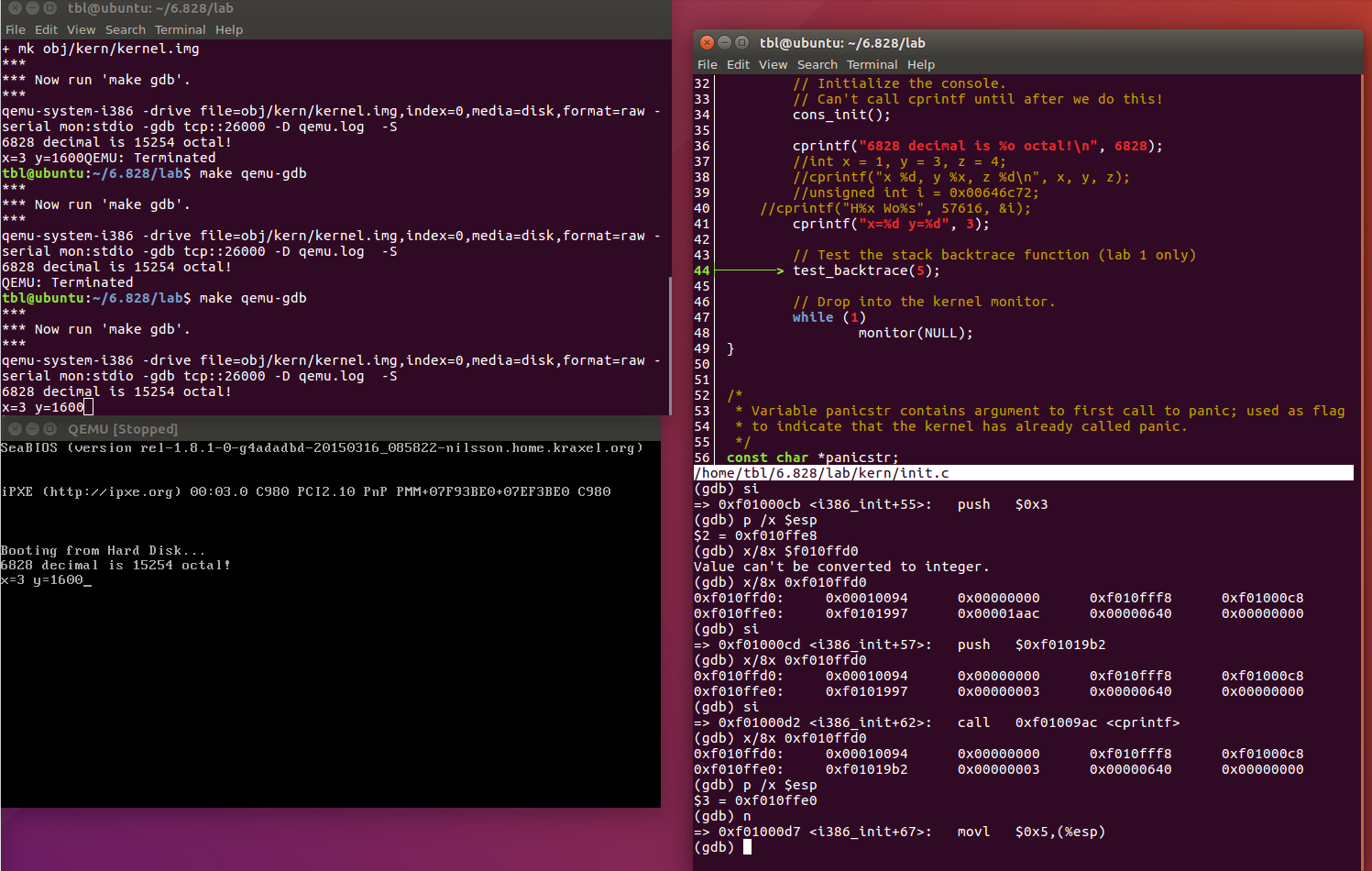
最后输出的结果为1600。在栈空间中,0x3对应的后面一个空间存放的是0x00000640 = 1600。也就是说,虽然,我们没有指定需要输出的变量,但是程序还是会从该变量的后面读取相应的内存并且输出。
Q6: 如何函数压栈的顺序为从左到右,那么cprintf应该怎么修改,使得其能够正确的输出?
这个答案我不确定,感觉是va_arg首先通过fmt确定整个输出的大小,然后找到头,移动方向与原来相反。
有的答案说的是int cprintf(..., const char *fmt)感觉不对。(欢迎大佬来讨论)
The Stack
exercise 9
找到kernel初始化栈的地方。
kernel是如何为栈保留空间的
这段初始程序最后栈的空间分布
在entry.S中有这样一段代码进行初始化:
#part 1
movl $0x0,%ebp # nuke frame pointer
# exercise 11提示看这个文件内容,发现应该是这个地方暗示着栈的结束。
# Set the stack pointer
movl $(bootstacktop),%esp
# part 2
bootstack:
.space KSTKSIZE
.globl bootstacktop
# part 3
#define KSTKSIZE (8*PGSIZE)
在实际运行的时候,进行了这样的初始化:
9│ 0x10002f: mov $0x0,%ebp
10│ 0x100034: mov $0xf0110000,%esp
1 PGSIZE=4096,通过计算,虚拟地址为0xf010f000~0xf0117000, 对用物理地址0xf010f000~0x00117000,并且栈空间大小为32KB。
因为栈是从高地址向低地址变化的,esp是栈的最低的地址。
ebp是栈底,高地址位。
一般产生函数调用时,会有以下的模式套路:
push $ebp
mov $esp $ebp
有了这样的模式之后,我们就能链式的进行溯源,查看调用的关系。
最后我们进行函数调用的时候,一般步骤,一定要注意顺序!
从右往左压入变量参数
压入函数返回地址,也就是调用的地方地址后面。
- 压入ebp,将esp赋值给ebp
- 保存寄存器值,局部变量
最终得到这样的结构图,红框表示一次完整的函数调用:
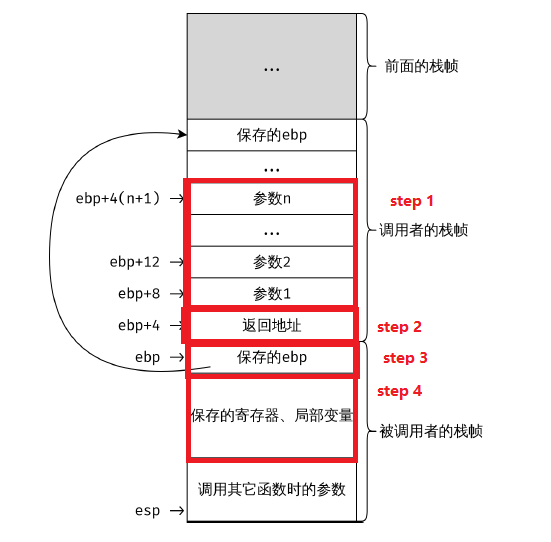
这样的一个栈的空间分布其实是非常有用的,这样当某个函数运行崩溃之后,我们可以不断的回溯ebp的值,并且读取栈空间中的值,就能够找到函数调用关系和,最终能够找到问题的源头。
exercise 10
在test_backtrace函数打上断点,观察每次递归时函数参数在栈中的变化。
同时,我们需要将该功能hook到monitor中进行调用。
什么是钩子函数,就是定义一个普遍的接口,当需要调用不同的函数功能的时候,往上添加就可以了,一般的定义如下:
// 定义钩子函数
struct Command {
const char *name;
const char *desc;
// return -1 to force monitor to exit
int (*func)(int argc, char** argv, struct Trapframe* tf);
};
//实例化
static struct Command commands[] = {
{ "help", "Display this list of commands", mon_help },
{ "kerninfo", "Display information about the kernel", mon_kerninfo },
{"traceback", "traceback info", mon_kerninfo},
};
//具体的需要挂载到钩子函数上的实际函数
int
mon_kerninfo(int argc, char **argv, struct Trapframe *tf)
{
extern char _start[], entry[], etext[], edata[], end[];
cprintf("Special kernel symbols:\n");
cprintf(" _start %08x (phys)\n", _start);
cprintf(" entry %08x (virt) %08x (phys)\n", entry, entry - KERNBASE);
cprintf(" etext %08x (virt) %08x (phys)\n", etext, etext - KERNBASE);
cprintf(" edata %08x (virt) %08x (phys)\n", edata, edata - KERNBASE);
cprintf(" end %08x (virt) %08x (phys)\n", end, end - KERNBASE);
cprintf("Kernel executable memory footprint: %dKB\n",
ROUNDUP(end - entry, 1024) / 1024);
return 0;
}
//调用
for (i = 0; i < ARRAY_SIZE(commands); i++) {
if (strcmp(argv[0], commands[i].name) == 0)
return commands[i].func(argc, argv, tf);
}
exercise 11
完成mon_backtrace()函数,使得该函数能够展示调用时刻的
ebp, 函数返回时执行的指令地址eip(实际上eip指的是当前执行指令的地址,这里的含义不一样),和5个变量arg。
就是递归的查看函数调用的关系,输出栈空间的变化:
Stack backtrace:
ebp f0109e58 eip f0100a62 args 00000001 f0109e80 f0109e98 f0100ed2 00000031
ebp f0109ed8 eip f01000d6 args 00000000 00000000 f0100058 f0109f28 00000061
...
需要注意的点就是,我们前面知道ebp初始化为0,因此终止的条件就是0。
通过观察栈空间分布,返回地址就是ebp+1。
由于这个函数调用参数是相对固定的,因此我们输出5个参数。
实现的代码:
cprintf("Stack backtrace:\n");
uint32_t ebp, eip;
for(ebp=read_ebp(); ebp!=0; ebp=*((uint32_t *)ebp)){
eip = *((uint32_t *)ebp+1);
cprintf(" ebp %08x eip %08x args %08x %08x %08x %08x %08x\n",
ebp, eip, *((uint32_t *)ebp+2), *((uint32_t *)ebp+3),
*((uint32_t *)ebp+4), *((uint32_t *)ebp+5), *((uint32_t *)ebp+5),
*((uint32_t *)ebp+6));
}
exercise 12
完善debuginfo_eip(eip),使得调用该函数,我们能够得到下面的信息:
- 文件名称
- 代码行号
- eip在函数内字节数的偏移
并且按照下面的格式进行输出:(有用的函数printf("%.*s", length, string),该输出表示最多展示length的字符个数,若小于该值则全部输出)
ebp f010ff78 eip f01008ae args 00000001 f010ff8c 00000000 f0110580 00000000 kern/monitor.c:143: monitor+106
首先看看我们能够拿到什么信息用来分析,使用命令objdump -G obj/kern/kernel,得到如下的部分输出:
tbl@ubuntu:~/6.828/lab$ objdump -G obj/kern/kernel | head -n 100
obj/kern/kernel: file format elf32-i386
Contents of .stab section:
Symnum n_type n_othr n_desc n_value n_strx String
1 2 3 4 5 6 7 //改行是我自己加的
-1 HdrSym 0 1269 0000197e 1
0 SO 0 0 f0100000 1 {standard input}
1 SOL 0 0 f010000c 18 kern/entry.S
2 SLINE 0 44 f010000c 0
3 SLINE 0 57 f0100015 0
4 SLINE 0 58 f010001a 0
5 SLINE 0 60 f010001d 0
6 SLINE 0 61 f0100020 0
7 SLINE 0 62 f0100025 0
8 SLINE 0 67 f0100028 0
9 SLINE 0 68 f010002d 0
10 SLINE 0 74 f010002f 0
11 SLINE 0 78 f0100034 0
12 SLINE 0 81 f0100039 0
13 SLINE 0 84 f010003e 0
14 SO 0 2 f0100040 31 kern/entrypgdir.c
15 OPT 0 0 00000000 49 gcc2_compiled.
16 LSYM 0 0 00000000 64 int:t(0,1)=r(0,1);-2147483648;2147483647;
17 LSYM 0 0 00000000 106 char:t(0,2)=r(0,2);0;127;
参考Stab的结构体,对应2-6列:
struct Stab {
uint32_t n_strx; // index into string table of name
uint8_t n_type; // type of symbol
uint8_t n_other; // misc info (usually empty)
uint16_t n_desc; // description field
uintptr_t n_value; // value of symbol,就是执行的地址
};
第七列是stabstr。
上面的内容还是很杂乱,我们看到二分搜索的主要类型有N_SO(源文件名称),N_FUN(函数名称)等等。
我们将上面的内容输出来看看:
objdump -G obj/kern/kernel | grep "SOL"
1 SOL 0 0 f010000c 18 kern/entry.S
176 SOL 0 0 f0100189 2985 ./inc/x86.h
178 SOL 0 0 f010018f 2970 kern/console.c
180 SOL 0 0 f0100193 2985 ./inc/x86.h
182 SOL 0 0 f0100199 2970 kern/console.c
201 SOL 0 0 f01001e8 2985 ./inc/x86.h
203 SOL 0 0 f01001ee 2970 kern/console.c
206 SOL 0 0 f01001fe 2985 ./inc/x86.h
208 SOL 0 0 f0100206 2970 kern/console.c
230 SOL 0 0 f01002dc 2985 ./inc/x86.h
232 SOL 0 0 f01002ea 2970 kern/console.c
248 SOL 0 0 f0100311 2985 ./inc/x86.h
250 SOL 0 0 f0100323 2970 kern/console.c
252 SOL 0 0 f0100326 2985 ./inc/x86.h
254 SOL 0 0 f0100329 2970 kern/console.c
256 SOL 0 0 f010033a 2985 ./inc/x86.h
258 SOL 0 0 f0100340 2970 kern/console.c
260 SOL 0 0 f0100345 2985 ./inc/x86.h
262 SOL 0 0 f0100357 2970 kern/console.c
264 SOL 0 0 f010035a 2985 ./inc/x86.h
266 SOL 0 0 f010035d 2970 kern/console.c
268 SOL 0 0 f0100369 2985 ./inc/x86.h
270 SOL 0 0 f0100384 2970 kern/console.c
291 SOL 0 0 f01004ba 2985 ./inc/x86.h
293 SOL 0 0 f01004c2 2970 kern/console.c
295 SOL 0 0 f01004cc 2985 ./inc/x86.h
297 SOL 0 0 f01004e2 2970 kern/console.c
340 SOL 0 0 f01005b5 2985 ./inc/x86.h
342 SOL 0 0 f01005bd 2970 kern/console.c
344 SOL 0 0 f01005c0 2985 ./inc/x86.h
objdump -G obj/kern/kernel | grep "FUN"
8 FUN 0 0 f0100040 2796 test_backtrace:F(0,20)
108 FUN 0 0 f0100094 2837 i386_init:F(0,20)
116 FUN 0 0 f01000f5 2855 _panic:F(0,20)
131 FUN 0 0 f010014c 2926 _warn:F(0,20)
174 FUN 0 0 f0100186 3012 serial_proc_data:f(0,1)
186 FUN 0 0 f01001a5 3036 cons_intr:f(0,20)
199 FUN 0 0 f01001e8 3091 kbd_proc_data:f(0,1)
244 FUN 0 0 f0100301 3137 cons_putc:f(0,20)
305 FUN 0 0 f01004ea 3173 serial_intr:F(0,20)
311 FUN 0 0 f0100506 3193 kbd_intr:F(0,20)
315 FUN 0 0 f0100518 3210 cons_getc:F(0,1)
329 FUN 0 0 f0100562 3227 cons_init:F(0,20)
369 FUN 0 0 f010066a 3274 cputchar:F(0,20)
374 FUN 0 0 f010067a 3300 getchar:F(0,1)
381 FUN 0 0 f010068b 3315 iscons:F(0,1)
429 FUN 0 0 f0100695 3981 mon_help:F(0,1)
436 FUN 0 0 f01006e4 4061 mon_kerninfo:F(0,1)
453 FUN 0 0 f0100794 4116 mon_backtrace:F(0,1)
477 FUN 0 0 f0100811 4170 monitor:F(0,20)
536 FUN 0 0 f0100945 4303 mc146818_read:F(0,4)
546 FUN 0 0 f010095c 4346 mc146818_write:F(0,20)
582 FUN 0 0 f0100973 4409 putch:f(0,20)
588 FUN 0 0 f0100986 4452 vcprintf:F(0,1)
598 FUN 0 0 f01009ac 4507 cprintf:F(0,1)
640 FUN 0 0 f01009c0 4684 stab_binsearch:f(0,20)
678 FUN 0 0 f0100ab6 4813 debuginfo_eip:F(0,1)
768 FUN 0 0 f0100d31 5135 printnum:f(0,20)
782 FUN 0 0 f0100de0 5253 getuint:f(0,9)
792 FUN 0 0 f0100e1a 5299 sprintputch:f(0,20)
802 FUN 0 0 f0100e37 5357 printfmt:F(0,20)
810 FUN 0 0 f0100e54 5422 vprintfmt:F(0,20)
918 FUN 0 0 f0101201 5529 vsnprintf:F(0,1)
936 FUN 0 0 f010124f 5595 snprintf:F(0,1)
974 FUN 0 0 f0101269 5699 readline:F(2,2)
1030 FUN 0 0 f0101342 5836 strlen:F(0,1)
1041 FUN 0 0 f010135a 5877 strnlen:F(0,1)
1051 FUN 0 0 f010137b 5915 strcpy:F(0,22)=*(0,2)
1060 FUN 0 0 f010139b 5985 strcat:F(0,22)
1071 FUN 0 0 f01013bd 6011 strncpy:F(0,22)
1083 FUN 0 0 f01013ea 6027 strlcpy:F(2,16)
1098 FUN 0 0 f0101425 6056 strcmp:F(0,1)
1110 FUN 0 0 f010144b 6110 strncmp:F(0,1)
1125 FUN 0 0 f0101483 6135 strchr:F(0,22)
还是能够发现很多整齐的用于调试的信息的。
首先分析这个二分的特点:
对某种类型的记录(第二列)进行查找的时候,内部有很多不同类型的记录,但是相同类型的地址n_value是单调增的。
尽管实验对二分的实现没有要求,我们可以进行一个简单的概括介绍:
首先初始化l=0, r=记录条数。
每次$mid = \frac{l+r}{2}$,并且找到是这个类型的记录,因为中间混杂着很多不是该类型的,所以需要不断mid--。
然后l.n_value和r.n_value对比mid.n_value进行常规的放缩。
最后我们左端一定是这个类型,地址也是这个数值的记录,右端不一定。
最后给一个例子进行理解。
// For example, given these N_SO stabs:
// Index Type Address
// 0 SO f0100000
// 13 SO f0100040
// 117 SO f0100176
// 118 SO f0100178
// 555 SO f0100652
// 556 SO f0100654
// 657 SO f0100849
// this code:
// left = 0, right = 657;
// stab_binsearch(stabs, &left, &right, N_SO, 0xf0100184);
// will exit setting left = 118, right = 554.
//
最终的实现:
在kdebug.c中:
stab_binsearch(stabs, &lline, &rline, N_SLINE, addr);
info->eip_line = lline > rline ? -1 : stabs[rline].n_desc;
monitor.c中:
cprintf("Stack backtrace:\n");
uint32_t ebp, eip;
struct Eipdebuginfo info;
//指针学习
//+1实际上偏移的是4bytes
for(ebp=read_ebp(); ebp!=0; ebp=*((uint32_t *)ebp)){
eip = *((uint32_t *)ebp+1);
debuginfo_eip(eip, &info);
cprintf(" ebp %08x eip %08x args %08x %08x %08x %08x %08x\n",
ebp, eip, *((uint32_t *)ebp+2), *((uint32_t *)ebp+3),
*((uint32_t *)ebp+4), *((uint32_t *)ebp+5), *((uint32_t *)ebp+5),
*((uint32_t *)ebp+6));
//.有截断的能力,*能够让eip_fn_namelen阶段字符串
cprintf(" %s:%d: %.*s+%d\n", info.eip_file, info.eip_line,
info.eip_fn_namelen, info.eip_fn_name, eip-info.eip_fn_addr);
}
最后测试结果:
